Hadoop Distributed File System:
Hadoop Distributed File System is a specially designed file system i.e., to store large amounts of data across a cluster of commodity hardware machines for streaming data access. Hadoop distribution file system in the primary storage system used by big data applications.
HDFS helps in providing high-performance access to data across Hadoop clusters. HDFS is deployed on low-cost commodity hardware. System failures are common when we use low-cost commodity hardware. But HDFS is designed to be highly fault-tolerant as it stores each data block in it in 3 replications(default, can be changed). So of one node fails in providing that block while processing, the program will not stop else it takes data from the another node where it's replica is placed on availability. This decreases the risk of catastrophic failure, even in the event that numerous nodes fail. The term used to allocate the number of replications is replication factor.
What are blocks? When HDFS takes input data, it breaks the information down into separate pieces called blocks and distributes the copies to different nodes in a cluster, allowing for parallel processing. In Hadoop 1.2.x default block size is 64MB and in a newer version it's size is 128MB. That means if we want to store a 200MB file in HDFS storage then, HDFS divides the 200MB file to 64MB+64MB+64MB+8MB 4 blocks and stores in nodes. And their replicas are stored in another node.For example, if the replication factor was set to 3 (default value in HDFS) there would be one original block and two replicas.
There are 5 daemons associated in HDFS. They are
• JobTracker: - Performs task assignment.
• TaskTracker: - Performs map/reduce tasks.
• NameNode: - Maintains all file system metadata if the Hadoop Distributed File System (HDFS) is used; preferably (but not required to be) a separate physical server from JobTracker
• Secondary NameNode: - Periodically check-points the file system metadata on the NameNode
• DataNode: - Stores HDFS files and handles HDFS read/write requests; preferably co-located with
TaskTracker for optimal data locality.
Hadoop servers are configured in the TaskTracker and DataNode in slave nodes.
First 3 are the services present within Master and remaining 2 are in Slave. These are back-end processes. Communication in between master and slave will be like – the only NameNode in master communicates with only DataNode and Job Tracker communicates with Task Tracker.
Under Replication and Over Replication:
Default replication factor is 3.
Over-replicated blocks are blocks that exceed their target replication for the file they belong to. Normally, over-replication is not a problem, and HDFS will automatically delete excess replicas. That’s how it's balanced in this case.
Under-replicated blocks are blocks that do not meet their target replication for the file they belong to. To balance this HDFS will automatically create new replicas of under-replicated blocks until they meet the target replication.
NameNode and its Functionalities:
NameNode i.e., the master should be configured with high-end devices. Slaves can be made of any Commodity hardware. Data Node communicates with the NameNode by heartbeat signals. These signals are sent to the NameNode by DataNode for every 3 seconds(default). For every 10th heartbeat signal, all blocks in the DataNode send the block report to the NameNode as NameNode stores the metadata of the cluster. Block report mainly contains how many blocks cluster holds, file directories, disk usage, current activities.
The NameNode assign the first block to the DataNode based on the network distance. The nearest DataNode within the cluster is the one which first responds to the NameNode’s request.
Recovering from the loss of a DataNode is relatively easy compared to that of a NameNode outage. In current versions of Apache Hadoop, there's no automated recovery provision made for a non-functional NameNode. The Hadoop NameNode is a notorious single point of failure (SPOF) Loss of a NameNode halts the cluster and can result in data loss if corruption occurs and data can’t be recovered. In addition, restarting the NameNode can take hours for larger clusters (assuming the data is recoverable).
DataNode and its Functionalities:
A DataNode stores data in the HDFS. A functional filesystem has more than one DataNode, with data replicated across them.
On start-up, a DataNode connects to the NameNode; spinning until that service comes up. It then responds to requests from the NameNode for filesystem operations.
Client applications can talk directly to a DataNode, once the NameNode has provided the location of the data. Similarly, MapReduce operations farmed out to TaskTracker instances near a DataNode, talk directly to the DataNode to access the files. TaskTracker instances can, indeed should, be deployed on the same servers that host DataNode instances, so that MapReduce operations are performed close to the data.
DataNode instances can talk to each other, which is what they do when they are replicating data.
· There is usually no need to use RAID storage for DataNode data because data is designed to be replicated across multiple servers, rather than multiple disks on the same server.
· An ideal configuration is for a server to have a DataNode, a TaskTracker, and then physical disks one TaskTracker slot per CPU. This will allow every TaskTracker 100% of a CPU, and separate disks to read and write data.
HDFS ARCHITECTURE:
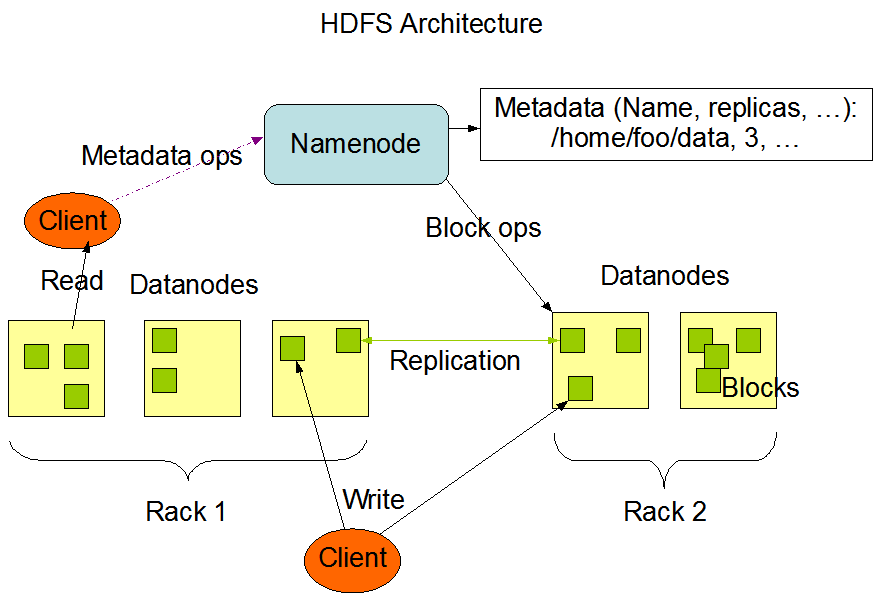
HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients. In addition, there are a number of DataNodes, usually one per node in the cluster, which manages storage attached to the nodes that they run on. HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. The DataNodes are responsible for serving read and write requests from the file system’s clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.
The NameNode and DataNode are pieces of software designed to run on commodity machines. These machines typically run a GNU/Linux operating system (OS). HDFS is built using the Java language; any machine that supports Java can run the NameNode or the DataNode software. Usage of the highly portable Java language means that HDFS can be deployed on a wide range of machines. A typical deployment has a dedicated machine that runs only the NameNode software. Each of the other machines in the cluster runs one instance of the DataNode software. The architecture does not preclude running multiple DataNodes on the same machine but in a real deployment that is rarely the case.
The existence of a single NameNode in a cluster greatly simplifies the architecture of the system. The NameNode is the arbitrator and repository for all HDFS metadata. The system is designed in such a way that user data never flows through the NameNode.
For further information regarding HDFS's
The existence of a single NameNode in a cluster greatly simplifies the architecture of the system. The NameNode is the arbitrator and repository for all HDFS metadata. The system is designed in such a way that user data never flows through the NameNode.
For further information regarding HDFS's
- Secondary NameNode
- Checkpoint Node
- Backup Node
- Import Checkpoint
- Balancer
- Rack Awareness
- Safemode
- fsck
- fetchdt
- Recovery Mode
- Upgrade and Rollback
- DataNode Hot Swap Drive
- File Permissions and Security
- Scalability












